Mafka全链路弹性伸缩演进策略
Comment业界全链路弹性伸缩调研
Apache Kafka的快速扩缩容方法
架构特点-重存储,轻计算
整体架构上,Kafka是以文件形式存储消息的,如下图所示,在每个kafka server内,又有多个文件来存储消息,每个文件叫做分片(partition)。
*注: 为了更容易理解kafka的扩容方式,以下介绍都省略了kafka内部controller,follower,以及副本和复制等方面的内容。

kafka server在接收到消息后,将消息顺序写的方式,落盘到磁盘文件上,用户在读取消息时也是以顺序方式读取消息。
因为整个文件读写都是顺序进行的,所以这种磁盘的使用方式速度特别快,效率也非常高,造就了Kafka高吞吐,低延迟的特性。
所以,整体上看,Kafka节点的资源压力主要来自于存储, 磁盘IOPS的使用,以及磁盘空间的使用,使用部分内存作为pageCache来加快读写,对CPU的使用特别少。
对于Kafka来说,集群上的扩容分以下几种场景:
| 场景 | 备注 |
|---|---|
| 单队列扩容 | 单个队列流量徒增,单个业务大促等 |
| 多队列扩容 | 多个队列一起扩容 |
| 缓解存量节点压力 | 缓解单个节点的压力,比如磁盘容量,IOPS资源不足的问题,迁移部分分片到新增的节点上 |
| 集群整体扩容 | 依据集群整体数据指标,周期性做整体扩容,整个集群增加新机器,集群内所有分片做全量重平衡 |
针对这四种业务场景,主要由以下四种扩容方法:
A、第一种、扩容分片(集群内扩容)
如下图所示,一个kafka集群包含3个节点,整个集群有一个主题A,它有一个分片。当这个主题的量在增大以后,一个分片无法满足业务方消息的生产速度时,就需要扩容。

当这个主题的量增大以后,一个分片无法满足业务方消息的生产速度时,可以扩容多个分片来分担写入请求。如下图所示,主题A扩容为两个分片,此时两个分片共同承担客户端的消息的写入,如果消息的总写入量是10k/s的话,每个分片承担一半,各自5k/s。

上边这种扩容,把主题A的两个分片都放到了节点1上。但是每个kafka server的磁盘容量,以及磁盘的IOPS是有限的,当超限以后,单台kafka server的资源就会被用尽。
这时,可以再扩容分片,并将新的分片分配到其他节点,这时主题A有3个分片,每个分片承担1/3的写入量。

以上集群内的扩容方式,实际上Kafka在运行时,一般是大集群的运行状态,集群创建时都有一定的容量冗余。
B、第二种,扩容集群节点,承担新的分片
如上边所述,当某个队列的容量不够时,第一种方法是在集群内通过扩容分片的方式来扩容。但是当整个集群内,每个节点的磁盘容量或IOPS都不足时,就需要用到第二种方法,扩容集群。
在当今云原生时代下,业界主要使用的是k8s 容器化来协助扩容。

如上图,扩容前,集群只包含3个节点,broker 1 ,broker 2和broker 3,如果kafka broker实现容器化部署后,使用k8s operator可以手动或编程的方式,快速新建两个新的实例 broker4和broker5,并加入到集群内,整个过程在容器资源充足的情况下,用时是秒级(<60s)别的,
当然,这两个新节点只有kafka服务在运行,并未承接新的数据。要想快速承接新的数据(消息),可以把新增加的分片放置到新的节点上,快速分担流量,就是上边的集群内扩容分片的方法,如下图。

C、第三种,扩容集群,迁移存量分片
可以对原集群节点上的存量队列分片做移动,将存量分片移动到新增的机器上,来减轻老节点的负载,如下图所示。
通过把老节点broker1,broker2,broker 3上的分片,移动到新的节点上,来减轻老节点的磁盘和IOPS压力。

使用这种方法时,当需要迁移的分片数据比较大时,会比较耗时,Kafka官方公司对此有一个功能增强,叫做分层存储。
所谓分层存储,就是将时间比较近的消息数据存放在kafka server机器本地,比如3个小时内的数据,将稍微久的数据存放在廉价存储上,比如S3、Hadoop或EBS上,如下图所示:

开启分层存储后,历史数据迁移到外部存储上,kafka节点本地数据减少:

分层存储有两个个优势:
- 因为本机存储的数据变少了,提升了集群的磁盘容量,也减轻了磁盘的都请求压力,等于变相的扩容了集群。
- 因为本机存储的数据变少了,上边第二种扩容方法里,迁移分片时,挪动的数据也减少了,提高了分片的迁移速度。
D、第四种,存储任务交由外部组件
这种方法比较简单,拿外部存储来替换本地磁盘,比如Amazon EBS,部署方式如下图,本地Kafka集群可以不配置或少配置磁盘,部署时磁盘地址挂接到EBS上:

在需要扩容集群的时候,可以分别扩容Broker和 EBS 磁盘存储。Kafka集群扩容时,可以依靠k8s operator快速创建Kafka实例;而磁盘容量或IOPS需要扩容时,交由EBS来处理。
方案优点:
集群扩缩容比较快。当CPU和内存达到上限后,可以由k8s operator快速扩容kafka实例;当磁盘容量、IOPS达到上限后,kafka自身无需扩容,可以直接扩容EBS。
Kafka集群宕机时,集群恢复速度快。kafka broker可以快速起一个新的实例起来,挂接到原节点对应的EBS上。不需要上边那样迁移分区数据。
kafka集群可以缩小副本数量。由于EBS自身有多副本容灾机制,因此kafka的副本可以适当缩小,比如从3副本缩小到2副本。
方案劣势:
- kafka zero copy特性无法使用,数据必须从外部存储拉取到kafka节点上,经过内核态和用户态的转换,消费性能会下降
- 多了一层网络访问,增加一个网络RTT时间,延迟受网络影响较大,性能可能会降低。

Apache Pulsar 的快速扩缩容方法
Pulsar实际上是两个开源组件的组合,Pulsar集群+BookKeeper集群,下图是Pulsar的架构概览:

Pulsar架构简述:
- Pulsar依赖一个开源项目Apache BookKeeper,使用它来做消息存储,而pulsar本身是一个无状态服务。
- Apache BookKeeper是一个分布式的日志条目(log entry)存储服务。
- Pulsar和b ookeeper都使用zookeeper来存储自己的元数据,并在启动时往zookkeeper上注册节点,来供其他节点或客户端发现自己。
- zookeeper同时负责监控pulsar和bookkeeper的健康状态。
由此可⻅,Pulsar是一个典型的“计算+存储”类型的消息队列,Pulsar本身只做消息队列层的概念抽象逻辑,真正的消息数据落地在BookKeeper中。
在扩容时,如果是因为“计算”不足,则可以直接扩pulsar集群,因为这个集群是无状态的,可以由k8s operator来快速实例话容器。
如果是因为”存储不足”,则可以直接扩容bookeeper,但客户端在写入bookeeper时一直保持Write Quorum数量,如下图所示。

pulsar在扩缩容方面的优势和劣势如下。
优势:
- pulsar集群因为是无状态节点,所以扩容速度比较快。
- bookkeeper集群扩容速度也很快,新加入的节点可以快速分担集群的压力。
劣势:
- bookeeper集群在节点宕机后,仍然要迁移宕机节点的数据到其他节点上,需要一段时间。
- bookeeper集群在扩容后,因为能很快使用新的机器,导致新的fragement会创建到新节点上,在消费数据时,需要跳跃到多个节点上拿数据,性能损失比较大。
Apache RocketMQ 快速扩容方法
4.0 及以前版本
如下图所示,RocketMQ的集群是由多对主从节点在组成的,每一个对主从机器都是一个部署单元,消息数据可以分散在多个单元上。

在这种架构下,扩容集群时,只需要构建更多的主从对即可,新的单元可以很快分担流量。
RocketMQ在快速扩容方面的优势和劣势如下
优势:
- 新加入的部署单元可以很快分担队列流量
劣势:
- 需要手动指定新单元需要分担流量的队列,在集群内队列数量很多时,这个操作比较繁琐。
- 由于RocketMQ没有像Kafka一样的集群迁移操作,当扩容新的单元后,新数据落到了新节点上,老数据依然在老节点上,消费这些数据只能还跳回到老节点消费,实际未分散消费带来的服务压力。
5.0版本(预览版,8月13日刚发布)
5.0版本则发生了很大的变化,初步从发布资料来看,架构采用了可分可合的存算分离方案,如下图所示:
*以下引用自infoQ: RocketMq 5.0架构
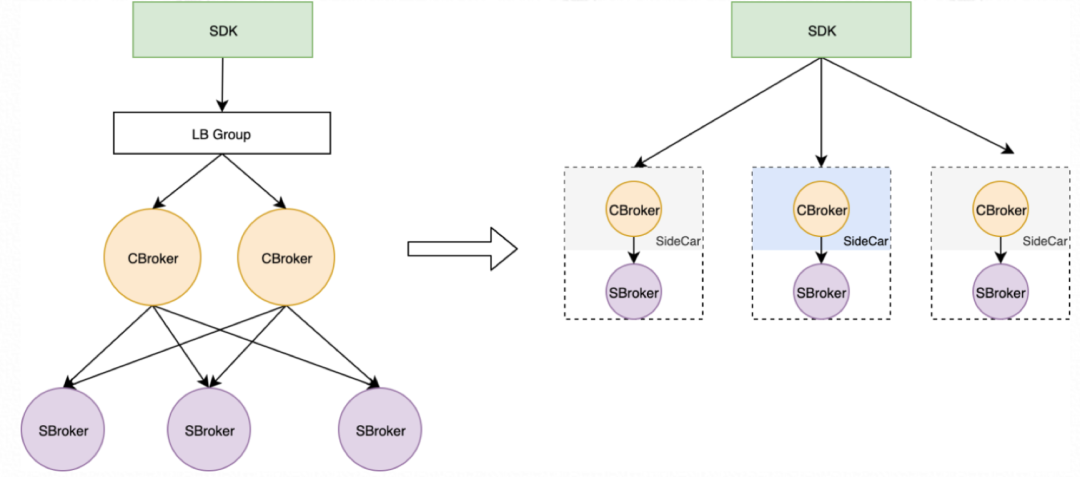
SDK: 用户客户端
LB Group: 负载均衡器
CBroker: 计算前端
SBroker: 存储后端
左侧是存算分离部署场景,右侧是放到一个机器上来部署,可以作为sidecar方式并存,也可以糅合到一个进程。
两种方式并存的架构体系,RocketMQ官方给出的理由是:
*以下引用自infoQ: RocketMq 5.0架构
通过可分可合的存储计算分离架构,用户可以同一进程启动存储和计算的功能,也可以将两者分开部署。分开部署后的计算节点可以做到“无状态”,一个接入点可代理所有流量,在云上结合新硬件内核旁路技术,可以降低分离部署带来的性能及延迟问题。而选择“存储计算一体化”架构,同时也能契合“就近计算”的趋势,也就是在最靠近数据的地方做计算。
林清山表示新版本在存储计算分离的架构选择上非常慎重:“首先我们认为在云上多租、多 VPC、多种接入方式的场景下是非常有必要的,存储计算分离后能够避免后端存储服务直接暴露给客户端,便于实现流量的管控、隔离、调度、权限管理。”
但是有利必有弊,除了带来延迟的上升、成本的增加以外,存储计算分离也会给线上运维带来巨大挑战。在大多数场景下,用户更希望的还是存储计算一体化的架构,开箱即用、性能高、延迟低、运维轻松,尤其是在大数据场景下,能够极大降低机器及流量成本。其实这个问题本质上还是由消息产品的特性决定的,消息相比于数据库,计算逻辑相对简单,拆分后往往会沦为无计算场景可发挥、存储节点也得不到简化的状态,这个从 Kafka 的架构演进也可以得到印证。”
“存储计算分离只是适应了部分场景,架构的演进还是要回归到客户的真实场景。”
- 解耦计算和存储,两者可以分开扩容。
- 依据“就近原则”,可以将计算单独部署在最靠近数据的地方。
- 云上多租、多 VPC、多种接入方式的场景下是非常有必要的,存储计算分离后能够避免后端存储服务直接暴露给客户端,便于实现流量的管控、隔离、调度、权限管理
- 有利必有弊,存算分离会带来延迟的上升,成本的增加,同时带来线上运维的巨大挑战。在多数场景下,用户还是希望存算一体化,开箱即用,高性能,低延迟,运维轻松。
另外,打听阿里内部RcoketMQ的开发人员,说RocketMQ已经开始接入云盘,但是现在没有官方资料放出来。
Mafka 快速扩缩容演进计划
Mafka的现有扩缩容能力
因为Mafka底层基于Kafka来研发,其底层扩缩容原理和上述的Kafka是一样的,总结Kafka和Mafka现有的扩缩容能力如下:

可以看出对于第三种扩容方法,存量数据迁移时,如果数据量比较大的时候,速度比较慢。
为了优化这个问题,可以有两种方案:
| 方案 | 优势 | 劣势 |
|---|---|---|
| 一、现有Mafka架构+分层存储(Mstore)(扩容方法C增强) |
|
|
| 二、Mafka + 外部存储 (扩容方法D、存算分离) |
|
|
参考:
Title: Mafka全链路弹性伸缩演进策略
Author: Rex Wang rexwang735@gmail.com
Date: 2021-07-22
Last Update: 2024-03-24
Copyright Declaration: Plz credit the original source when reposting
Aktie