Kafka去Zookeeper揭秘
Comment一、Kafka为什么要去Zookeeper ?
Zookeeper的作用
1 .依赖Zookeeper的一致性选举
Kafka集群有多个节点组成,在管理集群级别的任务和数据时,必须有一个主来充当指挥者,Kafka内将这个主节点命名为Controller。在集群第一次启动或是Controller宕机时,集群内每个节点都会去争取当选Controller,在复杂网络环境下,要形成一个一致性的选举结果,目前这个任务是交由Zookeeper来完成的,各个节点在Zookeeper上抢占一个临时节点来当选,Kafka集群内部并未实现一致性协议。类似的主节点选举还包括每个分区的主副本(leader replica)。

2 .依赖Zookeeper的存储和Listener监听回调
Kafka的元数据,比如topic,partition,AR(assiged replica),ISR,consumer等信息都存储在Zookeeper上,由Controller负责管理。另外,Controller还注册了很多监听器(Listener),比如创建topic,扩容
parttion,ISR发生变化,broker节点上下线,partition重新分配,删除topic等,都是由admin工具或broker先在Zookeper上挂节点,触发Controller的监听器回调,由Controller执行具体的操作。
使用Zookeeper的劣势和不足
元数据加载速度慢
上边说过,Zookeeper存储了Kafka集群所有的元数据,集群的Controller每次启动时,都需要将所有的元数据从Zookeeper上全量拉取一次,试想当集群的broker节点、topic、consumer或partition数量线性增⻓
起来后,每次加载全量元数据的时间势必会很⻓,在此之间Controller是无法响应和工作的,这样势必会影响整个集群的可用性。此外zookeeper也不适宜存储大量的数据,读写qps的增加,以及leader和follower的
切换,很容易造成⻓时间的java gc停顿,影响Z ookeeper的可用性。所以元数据加载慢这个问题,直接影响了集群的大小,比如集群内节点数量不能很多,partition数量不能很大,比如超过 100 万个。
数据一致性问题
上边说到,Controller会加载集群的所有元数据信息到内存内,加快读取速度,但是当集群的元数据需要变更时,Controller需要先将变更结果存储在Zookeeper上,再更新到本机内存,分成两步去操作和执行,这样做在实际运营过程中,很容易产生Zookeeper和内存数据不一致,甚至controller和其他节点的数据不一致,对集群可用性造成影响。另外,Controller在获取集群操作任务时,大多是由admin工具或其他broker在Zookeeper上挂节点,然后触发Controller的回调,回调执行完成后,再挂相应的watcher,整个过程中,很有可能漏掉一些watcher事件。所有这些问题产生的Zookeeper和内存数据的不一致,最终都必须重启
Controller节点来重新全量加载Zookeeper数据,来恢复整个集群的数据同一致性。
多维护一个组件
使用Zookeeper还会带来另外一个问题,多维护一个组件,对于当今企业应用要求来说,这不仅意味着多一个不稳定因素,Zookeeper的不可用会导致Kafka的不可用,另外还需要一个team来维护zookeeper服务,增加⻛险和成本。
二、Kafka去Zookeeper架构概览
使用Z ookeeper的K afka集群架构如下图所示,集群在部署的时候,除了部署Kafka集群外,还需要部署一个Zookeeper集群,Kafka集群每个节点都会有写入Zookeeper操作,除此之外,只有Controller才会读取Zookeeper上存储的元数据。

去除Zookeeper以后的集群部署如下:

集群有 5 个节点,BrokerA和BrokerE是普通的节点,BrokerB、BrokerC、BrokerD是单纯的Controller节点。这里Controller是指一个⻆色,这三个Controller节点组成了一个一致性集群(Quorum),三个节点会通过Raft算法选出一个Active的C ontroller担任整个集群真正的Controller,当Controller节点宕机或下线后,会重新选出一个新的Controller节点。
或是以下方式部署,每个Controller节点还可以同时起一个普通节点进程,在同一个Jvm内,但是在不同端口来接受服务请求。
去除Zookeeper之后,需要在部署集群节点时,在配置文件内写清楚每个节点的⻆色(Role),如果是Broker,就是普通节点,如果是Controller则是Controller节点,如果两个都有,则在同一个JVM内启动两个⻆色
的实例。同时还要写清楚集群Quroum的每个节点的IP,以及集群cluster ID等信息。
集群数据存储方面, 集群的topic、consumer、partition等信息,从创建到变更都存储在Raft Log(相关的Raft背景知识可以先了解下)里,为了和原有的Kafka Log保持一致性和兼容,这里的RaftLog直接使用了Kafka原有Log的格式,并追加了一些特殊字段,除此之外可以理解为普通的Topic Log,但是只有一个partition,而且没有副本,没有partition leader。普通Broker节点会通过监听器,(从本机Raft层)实时接收最新的元数据变更信息,并应用到自己的metadata cache内,供本机使用。
任务监听回调方面, 之前需要Controller监听Zookeeper节点所做的任务,比如Broker节点的上下线,是通过Broker节点和Active Controller节点之间的心跳来达成变更的,其他的比如创建topic、consumer、扩容partition等集群内任务,如果发到了普通节点,都会被转发给Active的Controller来执行,Active Controller将执行结果通过运行Raft算法来复制到Quorum的其他节点上,数据会在被各节点真正Committed(Raft Committed,这里需要了解一些Raft背景知识)之后,应用到本机的状态机内,形成metadata cache。
去除Zookeeper之后,集群的元数据在Quorum节点之内会以Raft Log方式来复制,因此当Controller宕机之后,新选出来的Active Controller本地就有全量数据,不需要再从其他节点拉取,这样就解决了上一部分说的“元数据加载慢”的问题,第二因为现在的元数据是以Raft Log的方式来存储和复制,也不存在“内存和Zookeeper”之间数据不一致的问题,由Raft来保障集群内所有节点上的元数据一致性。最后,去除了Zookeeper之后,因为数据就在Kafka内部,也不需要额外再维护另外一个组件。
三. Kafka Raft 算法
如果大家对Raft算法比较了解,我们拿Kafka Raft和传统的Raft算法做一个对比,就会比较容易理解。
标准Raft算法
传统的Raft算法如下图
*下图引用自Raft paper
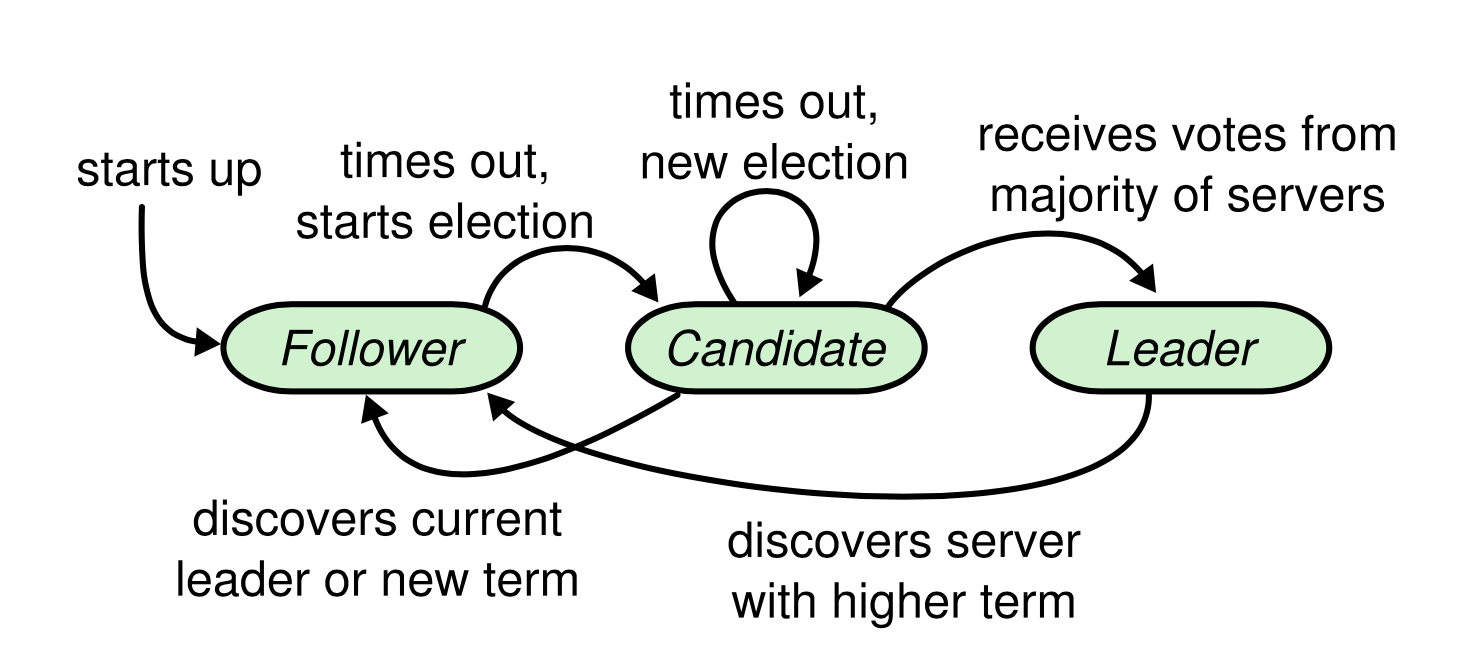
⻆色分类
为了更容易理解,我们把分布式一致性场景分为两种,一种是“正常场景”,就是服务正常运行期间,没有机器宕机,没有机器上下线,没有网络分区。另外一种是“异常场景”,就是前边说的反面,发生宕机,发生机器上下线,发生网络分区。
正常场景下,Raft集群内所有节点只有 2 中⻆色,Leader 和 Follower。
- leader: 集群内只有一个leader,负责接收客户端的请求,发送AE(AppendEntries)请求给follower,复制command或发送心跳。
- Follower:被动接受leader发来的心跳请求或是复制过来的command.
异常场景下,多了一种状态candidate
- candidate: 当某个节点决定参与leader选举时,会转换为这个状态。
⻆色转换
- Follower: 一个节点进入Quorum集群后,就是Follower状态,当经过election timeout 时间后还未收到AE请求的话,那么就转换为Candidate状态。
- Candidate: 当经过election timeout时间后,还未选举出Leader,重新进入Candidate状态,触发新一轮选举。
- Leader:当Candidate收集到足够多的Votes之后,就转换为Leader状态。如果Leader在接收到AppendEntries响应之后,发现了新的Epoch,那么就转换为Candidate状态。
提交流程
- 客户端发送submit请求(包含的具体内容是command)给leader.
- leader保存command到本地log里作为一个新的entry.
- leader发送AppendEntries请求给集群内其他的server,
- 当Leader收集到集群内多数派server的正确响应后,将comand应用到本地状态机。
- leader将上一步中状态机返回的结果返回给客户端
RPC请求类型
- AppendEntries 请求(简称AE请求): Leader发送给Follower的请求,不仅用来复制Raft Log,同时也用作心跳探活请求
- 参数:term、leaderId、prevLogTerm、prevLogIndex、leaderCommit、entries
- 处理逻辑:Follower检查自己的Log是否符合p revLogTerm、prevLogIndex,如果不符合的话,说明发生日志分歧,返回给leader追加日志失败。如果符合的话,追加自己的Log里。检查Leader发送来的leaderCommit index和自己Log里的最大index,两者取最小值作为自己最新的commitIndex,前进的index所附带的entries是本次新的committed entry,状态机监听到以后会apply这些entry内附带的command。
- RequestVote 请求(简称Vote请求)
- 参数:candidateTerm、candidateID、LastLogIndex、LastLogTerm
- 处理逻辑:如果candidateTerm大于小于本机Term则直接拒绝,如果本机Term和candidateTerm相等,candidate的lastLogTerm大于本机logTerm,或者这两个term相等而且candidate的l astLogIndex大于本机logINdex,这返回成功,赞成这个选举,否则返回失败。
Kafka Raft算法
Kafka Raft里节点的状态转换如下图所示,但是注意下,这个是KIP里计划的,实际上Kafka 3.0版本代码实现上没有Observer这个⻆色,也没有Observer到Voter的转换,这几个功能还未真正实现。
在Kafka Raft里,一些概念有不同的名词。比如Raft里的term,在kafka里称为epoch,Raft里的log index,在Kafka Raft里称之为offset
*下图引用自Kafka KIP-595
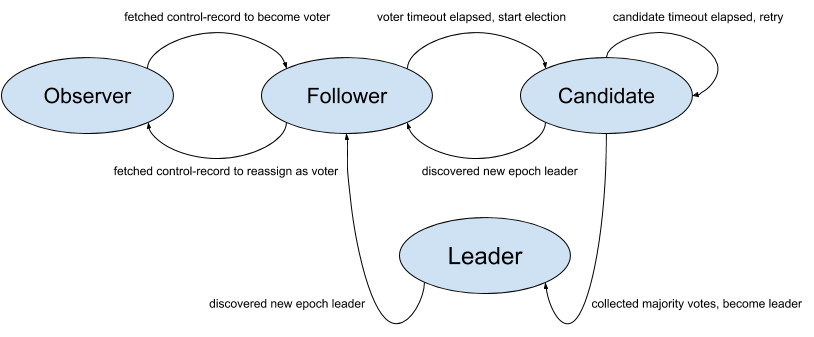
⻆色分类
正常场景下,整个quorum里的⻆色包含以下几个:
- leader:接受客户端请求。注意这里的客户端不是指kafka生产消费消息的客户端,是指controller,controller在处理一些集群内管理事务时,会生成一些command,这些command 会提交给 leader,运行一次raft算法。
- follower:主动从leader上拉取command,注意这点跟Raft是不一样的,在Raft里follower是一个被动⻆色,等待leader的AE请求。
- observer:不参与抢主,也不参与投票,只从leader拉取command,类似zookeeper里的observer,作为一个状态机的只读节点。注意,虽然KIP-595里定义了这个⻆色,到目前为止,在 3 .0版本的实现里它实际上是一个状态为unattached的节点。
异常场景下,会多几个⻆色:
- unattached:脱离状态的节点,一般是刚上线的新机器,之前没有参与过集群的任何事务,注意这个状态是代码实现里有的,没有在上图里标识出来。
- candidate: 某个节点决定竞选leader后,会转换为这个状态。
- voted:某个节点投了票之后会转换为这个状态
- resigned:集群的leader准备卸任时,会转换为这个状态。注意这个状态是代码实现里有的,没有在上图里标识出来。
总结下,Kafka Raft里每个节点会有 7 种状态,比原生Raft多出了 4 个状态observer、unattached 、voted和resigned.
⻆色转换
- Unattached: 这是节点启动的初始状态,任何一个节点启动来后,会先进入这个状态。 如果当前节点为Voter(也就是⻆色配置为Controller的节点),经过election timeout的时间后转换为Candidate。如果当前节点不是Voter,则发起拉取FR(FetchRequest)请求。
- Candidate:经过election timeout之后,开始进行back off,给与其他Candidate发起Vote的机会,这里就是Raft paper中说到的Random时间发起Vote。如果在election timeout之内的话,会发起Vote请求。
如果在back off 时间结束之后的话,会再次转换为Candidate,继续发起新一轮Vote。 在收到多数派节点的Vote支持之后,当选为Leader,转换为Leader状态。 - Voted:经过election timeout之后,转换为unattached状态,否则继续等待。
- Leader:在收到resign请求后,转换为resigned状态。
- Follower:经过election timeout 之后,转换为Candidate参与选举,否则发送FR请求,从Leader拉取最新的增量数据(依据上次拉取的Offset)。
- Resigned:leader在收到 resign请求后,会转换为这个状态,然后跟其他节点发送EndQuorum请求,代表卸任这个leader任期。
- Observer:Kafka 3.0版本中未实现这个⻆色。
提交流程
- Active Controller执行了一些集群内的任务,如果需要写入metadata数据的话,会提交给Raft leader(也就是Active Controller)。
- Follower发起Fetch请求,从Leader拉取自上次请求之后的新增数据,依据上次拉到的offset,leader返回新追加的数据。Leader查看Follower请求中的offset,比较多数派拉到的最小offset,前进
HighWaterMark,这里指的是标识已经被committed的数据。 - Unattached节点,也就是当前 3.0版本中的普通节点Broker,也会发起FR操作,从Leader拉取自上次请求之后的新增数据,具体处理流程和Follower相同。
- Follower和Unattached节点上,如果有增量的committed的数据,则会触发本机的metaDataListener的接收数据操作,这里的metaDataListener就是注册在Raft上的committed数据监听器。接收到的新数据会更新到本机的metadata cache中,供节点读取使用。
RPC请求类型
- Vote请求
- 参数:candidateEpoch、candidateId、lastOffsetEpoch、lastOffset
- 处理逻辑:处理逻辑和普通的Raft算法相同。
- BeginQuorum请求:leader发给q uorum里其他voter的请求。注意这个请求是标准R aft里没有的。其实这个请求的目的就是广播新当选的leader,因为在标准Raft里,心跳是由leader发出的,所以leader当选后发出心跳即可广播整个集群的新leaderID和leaderEpoch。但是kafka Raft在正常场景下都是依靠拉取(pull)来获得新的log的,没有从Leader发出的主动心跳请求,所以单加了这个。
- 参数:leaderId、leaderEpoch
- 处理逻辑:查看本机epoch是否和leader的e poch相同,不同的话更新epoch,转换为follower⻆色。
- EndQuorum请求:Kafka Raft新加的一个请求,作用是加速leader的优雅关闭。比如l eader在优雅关机的情况下,可以发出这个请求,主动通知其他Voter发起选举。如果么没有这个请求的话,其他Voter需要等待election timeout的而时间后才会发起新的选举,这无疑会延⻓集群无leader的时间。
- 参数:leaderId、leaderEpoch、preferredSuccessors
- 处理逻辑:接收到这个请求的voter会主动转换为candidate时间,但是会有一个不同的等待时间,这个等待时间是老的leader通过p referredSuccessors传给他的voter的。
- Fetch请求:这个是与标准Raft区别最大的地方,标准Raft是通过leader主动发起AE请求( push模式)给他节点,一方面复制log使用,另一方面作为心跳探活来使用。但是Kafka Raft是pull模式,所以log的拉取是依靠follower主动发起到leader的请求。这里需要介绍下Kafka Raft的snapShot,如下图所示,snapShot是Kafka节点里Kafka Raft的本机metadata数据的一个全量快照。Kafka会根据设定好的新增数据最大量来确定是否在log里某个offset新创建一个snapShot。

另外一个是在处理拉取请求时,leader需要比较Follower的日志状态。如下图所示,有些Follower的日志可能比leader少,比如(a)(b)。有些可能多,比如(c)(d)。有些情况有多又少,比如(e)(f)。leader需要根据不同的情况来处理,有些需要发送snapShot,有些需要告诉follower截取日志,有些正常的拉取,leader和follower根据请求和返回来前进自己的highWaterMark。
*下图引用自Raft paper

- 参数:currentLeaderEpoch、fetchOffset、lastFetchEpoch、logStartOffset
- 处理逻辑:follower的fetchOffset如果不在leader的log范围之内,说明是新加入的follower或者是follower因为什么原因log差距太远了,这种情况下leader会返回响应,让follower再次发起一个拉取snapShot的请求。第二种情况是拉取leader检查出follower的lastFetchEpoch和fetchOffset与leader本机的log不匹配,发生了日志分歧,这时leader会返回一个调度日志的epoch和offset。最后一种情况是,follower拉取的offset范围是正常的,这时leader会返回上次拉取到当前的新增数据,如果没有的话,就等待一个时间。如果拉取到数据了,这时leader就可以检查多数派已经拉到的offset index,前进自己的highWaterMark。
Follower在接收到leader的响应后,如果是要拉取snapShot,就发送snapShot拉取请求。如果发生了日志分歧,就开始截取日志,然后再发起拉取请求。如果是正常的返回,则比较leader返回的highWaterMark和本机的highWaterMark,看自己是否需要更新。
三. Kafka Raft思考和前瞻
以上就是Kafka去除Zookeeper的架构变更,和Kafka Raft的细节。虽然Kafka 2.8版本已经发布了KRaft模式作为Kafka 去除Z ookeeper预览,但是仍有一些重要的feature未实现。比如Quorum内节点替换,还有从非Raft模式到Raft模式的平滑滚动升级,这两项在实际的生产集群运营中都是必须的功能。
此外,Kafka Raft整个模块的实现,相对与整个Kafka系统来说相对独立,只有log层是和原有的Kafka log是共用,因此可以考虑抽离整个模块做成一个单独的lib库,替换一些服务依赖Zookeeper做一致性的功能,随服务一起发布。但这里有三个问题,第一,服务之前可能是无状态的,因为添加了Kafka Raft lib库之后变成了有状态服务,这样服务器的批量启停和替换必须得额外注意,不能全部关闭,因为Raft Quorum需要一定数量的节点才能运行。第二,因为Kafka Raft依赖磁盘来存储Raft log,而且每次追加Log时,必须是刷盘操作,因此对磁盘的性能和空间有一定的要求。第三,Zookeeper中实现的临时节点抢占操作、Listener回调等语义需要通过变通的方法来解决,因为原生Kafka Raft内没有这些api。
参考:
- KIP-595 、KIP-631
- Raft paper
Title: Kafka去Zookeeper揭秘
Author: Rex Wang rexwang735@gmail.com
Date: 2021-12-01
Last Update: 2024-03-24
Blog Link: https://wangjunfei.com/2021/12/01/Kafka%E5%8E%BBZookeeper%E6%8F%AD%E7%A7%98/
Copyright Declaration: Plz credit the original source when reposting
Aktie