时间轮算法分析和应用
Comment问题
时间轮是一个比较有趣的算法,他最早刊登在George Varghese和Tony Lauck的论文里。
问题的初衷是如何实现一个高效的定时器调度。比如有很多定时任务,每个任务的定时时间不一样,有1s 后,5s 后,1小时后,3天后,假设有很多个这样的任务,数千个或数万个,怎么通过程序来实现高效的调度每个任务,让他们在到期后顺利执行。
java中最直接的就是使用Timer类,使用 add方法增加一个定时任务。但是这种方法有几个问题:
- 定时任务需要Timer内的线程来执行,一个Timer在背后只有一个线程在执行,假设其中一个任务本身的执行时间太久,后边的任务就会被耽搁,特别是当有很多任务,比如成千上万个需要调度时
- 而且这个类还有一个问题,如果其中一个TimerTask在执行时抛出了异常,那么整个计时器会停止运行。
解决方法
下边来看看论文里讲的几种实现方法
总结一下,整个任务调度算法分为4种操作:
- 创建一个任务(start_timer)
- 取消一个任务(stop_timer)
- 时钟走一格,需要做的操作(per_tick_bookkeeping)
- 启动到期的任务 (expire_process)
方案1: 无序列表
假设有一个列表,每个元素存储一个任务,任务包含任务到期后要做的操作,以及任务的到期时间。
这时,我们通过程序模拟时钟在走动(tick),比如, 14:20:21, 14:20:22, 。。。按顺序推动时间走,时间每走一格,上边4个操作需要的时间复杂度如下:
- 开始调度一个任务(start_timer): 来了一个新的任务,我们把任务直接插入到列表尾部,时间复杂度O(1),每次插入后返回任务的指向指针,这样在取消任务时,就可以直接拿来操作。
- 取消一个任务(stop_timer): 如上,我们持有任务的指针, 假设我们使用双向链表来实现列表,直接操作指针即可完成。
- 时钟走一格,需要做的操作(per_tick_bookkeeping):因为整个列表里,每个任务的过期时间不一样,我们需要遍历整个列表,找到当前这一时间格时,过期里边所有任务。所以时间复杂度度是O(n)
- 启动到期的任务 (expire_process):这个操作只要找到过期的任务,直接操作即可,不需要额外的时间处理。
因为取消一个任务,启动到期任务两个操作,只要我们保存任务的指针,即可完成,时间复杂度都是O(1),因此后续的方案都不再赘述他们。
方案2: 有序列表
将列表维护为一个有序列表,把任务按照时间到期的顺序做排序,最早到期的任务排在最前面。
这样,算法的操作如下:
- 开始调度一个任务(start_timer): 来一个新的调度任务时,需要将任务插入到有序列表相应的位置,按照过期时间排序,最坏时间复杂度是O(n)。
- 时钟走一格,需要做的操作(per_tick_bookkeeping):直接从列表开头开始找任务,和当前时间做比较,因为最先到期的都在列表开头,因此时间复杂度基本是常数,是O(1)的时间复杂度。
方案3: 树形结构
将列表维护为一个非平衡二叉树,堆或者前序、或后序遍历树,这种情况下,插入一个任务的时间复杂度可以降低到O(logn)
方案4: 简单时间轮
时间轮方式。将所有任务的换算为多少秒或毫秒(Interval)后到期,维护一个最大过期值(Interval)长度的数组。比如有10个任务,分别是1s,3s,100s 后到期,就建一个100长度的数组,数组的index就是每个任务的过期值(Interval),当前时间作为第一个元素,那么第二个元素就是1s 后到期的任务,第三个是2s 后到期的任务,依次类推。当前时间随着时钟的前进(tick),逐步发现过期的任务。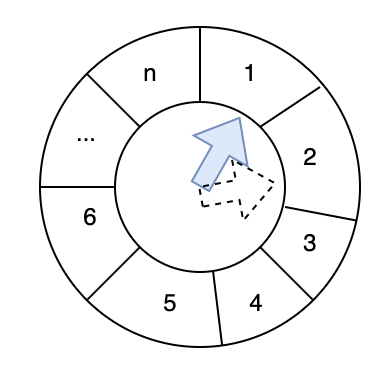
这种方案的时间复杂度:
- 开始调度一个任务(start_timer): 来一个新的调度任务时,换算任务的到期时间为到期值(Interval),直接放入相应的数组元素内即可,时间复杂度是O(1)。
- 时钟走一格,需要做的操作(per_tick_bookkeeping):时钟走一格直接拿出这一格内的任务执行即可,时间复杂度是O(1)。
方案5: hash有序时间轮
方案4虽然很完美,所有的操作时间复杂度都是O(1),但是当任务最大到期时间值非常大时,比如100w个时,构建这样一个数组是非常耗费内存的。可以改进一下,仍然使用时间轮,但是是用hash的方式将所有任务放到一定大小的数组内。 这个数组长度可以想象为时间轮的格子数量,轮盘大小(W)。
hash的数值仍然是每个任务的到期值(Interval),最简单的是轮盘大小(W)取值为2的幂次方,Interval哈希W后取余,余数作为轮盘数组的index,数组每个元素可能会有多个任务,把这些任务按照过期的绝对时间排序,如方案二一样,最先过期的排在最前面,这样就形成了一个链表,或者叫做时间轮上的一个桶。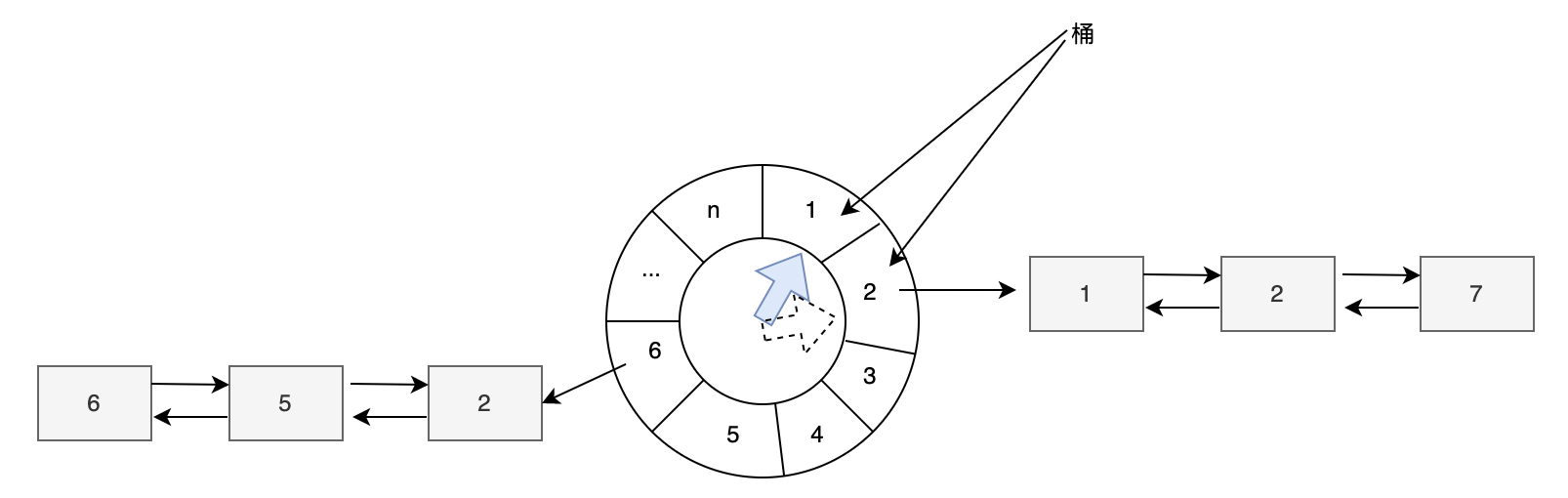
这种方案的时间复杂度:
- 开始调度一个任务(start_timer): 来一个新的调度任务时,换算任务的到期时间为到期值(Interval),hash 一下时间轮的轮盘大小,放置在余数为index的格子内,同时需要放置有序列表合适的位置上,这样最坏的时间复杂度为O(n)(放置的位置刚好在列表最后的一个元素),最好的时间复杂度为O(1)(放置的位置在列表的第一个位置)。平均时间复杂度为O(1),当轮盘大小(W) > 所有任务的个数n时,并且hash函数能将所有任务均匀的分布在每个数组内。
- 时钟走一格,需要做的操作(per_tick_bookkeeping):时钟走一格直接拿出这一格内的任务列表,从列表开头开始拿出任务过期时间的绝对值和当前时间做对比,过期的直接拿出,触发过期操作。
方案6: hash无序时间轮
因为方案5在执行添加任务时,需要和hash 在同一时间格子内的有序任务列表内的元素做比较,放在合适的位置上,最坏时间复杂度是O(n)。如果要摆脱这个问题,需要可以将数组元素内的列表作为无序列表。
开始调度一个任务(start_timer): 来一个新的调度任务时,换算任务的到期时间为到期值(Interval),hash 一下时间轮的轮盘大小,放置在余数为index的格子内,商值保存在任务内,因为余数数组元素内的列表是无序数组,直接放置在末尾即可,时间复杂度是O(1)。
时钟走一格,需要做的操作(per_tick_bookkeeping):时钟走一格直接拿出这一格内的任务列表,从列表开头开始,逐个检查列表内的元素,如果商值为0,则直接过期数组,如果非0,则需要做减一操作,等待下一个时钟周期。这里的最坏时间复杂度为O(n),因为需要遍历列表内的每一个元素。平均时间复杂度是O(1),当轮盘大小(W) > 所有任务的个数n时,并且hash函数能将所有任务均匀的分布在每个数组元素内。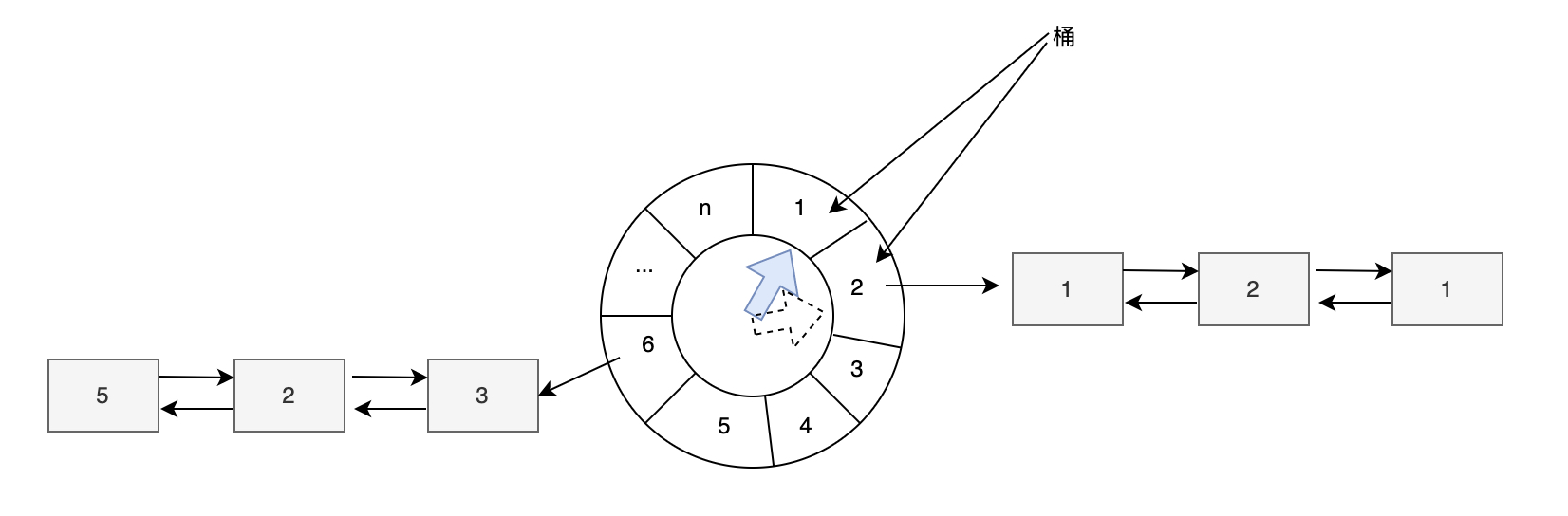
方案7: 多级时间轮
这个方案是直接模拟时钟,将天、小时、分钟、秒作为4个不同的时间轮,每个时间轮都有一个单独的数组,来模拟时间轮盘。
注意,这个方案的核心思想是将最大过期时间值Max(Interval)按级别,分散在不同的时间轮内来标识,以此来用比较少的数组元素来表示最大值Max(Interval)的过期时间。秒级时间轮转一圈刚好是1分钟,分钟级时间轮转一圈是一小时,小时级时间轮转一圈是一天,天级时间轮转一圈可以是100天或1年,轮盘大小可以根据需要承接的最大时间段来确定。比如天级轮盘大小设置为100,小时级设置未24消息,分钟、秒级都设置为60个,那么可以承接的最大过期时间值Max(Interval)(每级轮盘不超额放置)将是100*24*60*60=864万,而实际底层存储我们只使用了100+24+60+60=244大小的数组。
时间轮驱动是由最小级开始的,秒级时间轮转一圈,分钟级时间轮转一个格子。分钟级时间轮转一圈,小时级时间轮转一个格子,小时级时间轮转一圈,天级时间轮转一个格子。假设一个任务的过期时间是3天,10小时,15分,10秒。那么天级时间轮也是拿时间段来hash轮盘大小,比如 hash 完是3那么就放到第3个格子,小时级时间轮同样的做hash余数作为数组的index,放置到相应的格子内,依次类推。当天级时间轮,过期一个时间时,需要将任务踢到下级时间轮,看是否在下级时间轮的范围时间内,如果能放进去,则继续用下级时间轮来推动,否则再继续往下级时间轮来踢,如果所有的时间轮都无法承接这个过期任务了,那么就启动定时任务。还拿这个任务来做例子,如果天级时间轮发下,3天已经过完了,就会把这个任务踢到小时级时间轮,小时级时间轮发现10小时、15分、10秒在自己可以承担的时间范围内,则放到相应的格子内。10小时过完以后,小时级时间轮又会把这个任务踢到分钟级,分钟级过完后,又会踢到秒级,秒级过完后,发现已没有更下级时间轮了,就直接启动定时任务。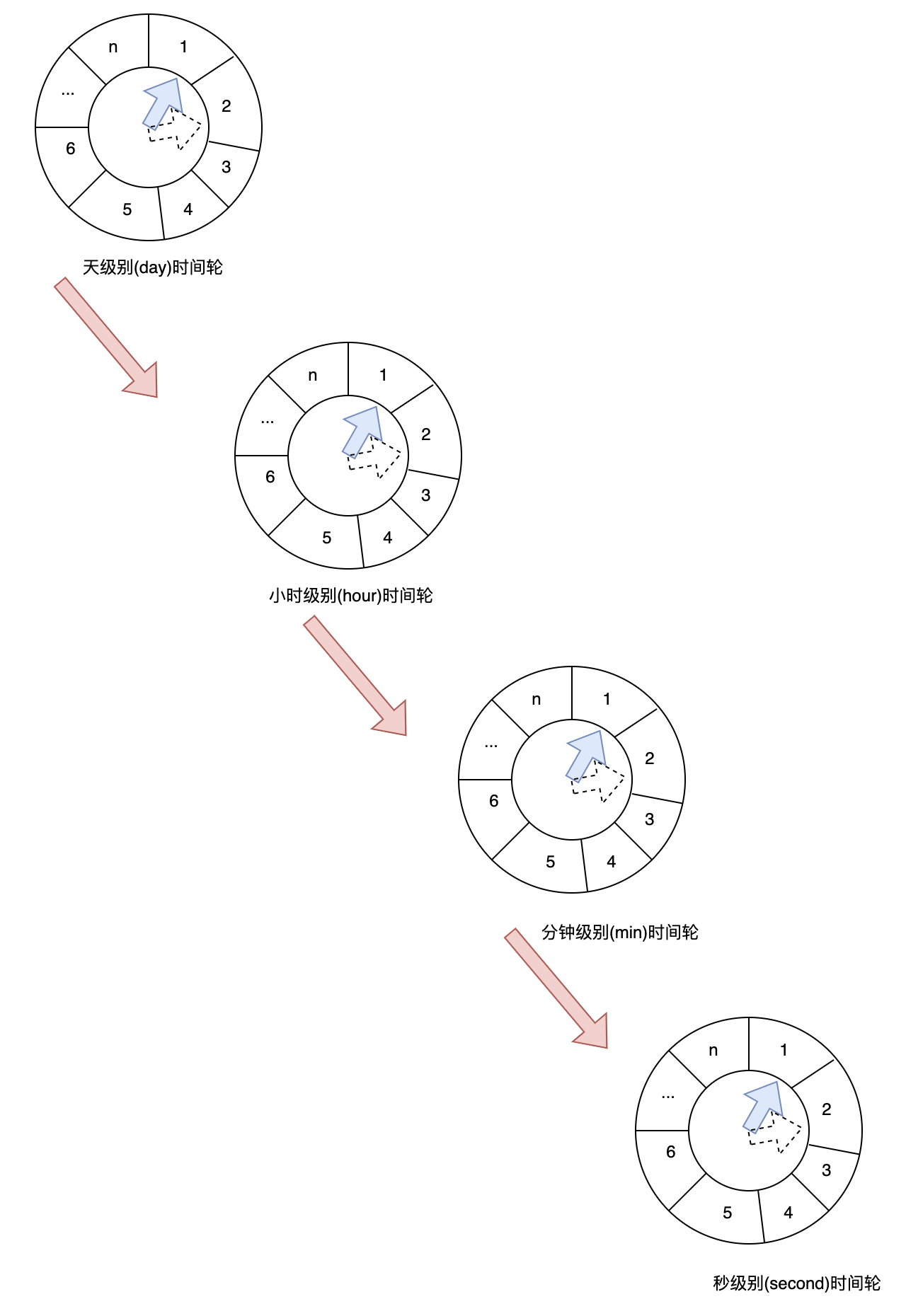
这种方案的时间复杂度:
- 开始调度一个任务(start_timer): 来一个新的调度任务时,换算任务的每个级别,天、小时、分、秒的到期时间为到期值(Interval),hash 一下时间轮的轮盘大小,放置在余数为index的格子内,时间复杂度是O(1)。
- 时钟走一格,需要做的操作(per_tick_bookkeeping):时钟走一格直接拿出这一格内的任务列表,从列表开头开始,逐个检查列表内的元素,检查任务是否还有下级时间轮,没有的话直接过期任务,有的话踢到下级时间轮内,比如某个任务的过期时间是3min50后,那么个任务会存储在分钟时间轮3那个桶里,当这个桶过期后,查看剩余的时间是否能放到下一级时间轮,发现剩余50min 就将任务放到秒级时间轮的50那个桶里,等待过期;并且这个方案的平均时间复杂度是O(1),前提是当轮盘大小(W) > 所有任务的个数n时,并且hash函数能将所有任务均匀的分布在每个数组元素内。
注意:在n<W时,即过期任务个数小于轮盘大小W时,方案6、7的平均时间复杂度都是O(1),但是在时钟每走一格,需要做的操作里(per_tick_bookkeeping),方案6和方案7会有一些细小的区别,会影响到方案选择:
设T为所有过期任务的平均时长跨度(开始到结束的时间间隔)
设M为所有数组的元素个数总和,即时间轮大小
设m 为多层时间轮的层数那么方案6里,每个任务的总用时间为:
c(6)*T/M
c(6)是时钟每走一格,需要将任务递减1需要的用时。如果任务需要递减T/M次,那么任务的总用时就是c(6)*T/M。相对于方案7,每个任务的总用时间为:
c(7)*m
c(7)是踢到下一级时间轮的用时,m 是时间轮的最大层级,所以每个任务的总用时即c(7)*m如果有 n 个定时任务,那么每个时间单位内的任务的用时是:
方案6是: n*c(6)/M
方案7是: n*c(7)*m/T因为c(6),c(7)两项的用时基本是常数,m值也不会很大(因为层级不可能很多),这样一比较就会发现,虽然方案6、方案7的start timer都一样,时间复杂度都是O(1),但(per_tick_bookkeeping)还是有差别的(虽然平均时间复杂度都是O(1)),根据上边的公式,如果M大那么应该选方案6(除数大),如果T大应该选方案7。
总结
综合比较一下上述的5个方案:
| 方案 | start_timer | stop_timer | per_tick_bookkeeping | 备注 |
|---|---|---|---|---|
| 方案1:无序列表 | O(1) | O(1) | O(n) | |
| 方案2:有序列表 | O(n) | O(1) | O(1) | |
| 方案3:树、堆结构列表 | O(log(n)) | O(1) | O(1) | |
| 方案4:简单时间轮 O(1) | O(1) | O(1) | 当时间跨度很大时,比较耗内存。 | |
| 方案5:hash 有序桶时间轮 | O(n)最坏情况 | O(1)平均时间复杂度 | O(1) | O(1) |
| 方案6:hash无序桶时间轮 | O(1) | O(1) | O(n)最坏情况 O(1)平均时间复杂度 | [1]* |
| 方案7:多层时间轮 O(m) | O(1) | O(1)平均时间复杂度 |
[1]*per_tick_bookkeeping占用时间: 时间轮轮盘比较大时选择方案6,任务的平均过期时间长度比较长时选择方案7
比较上边几个方案,从时间复杂度来看,最好选择方案5、6、7。但是方案5在创建一个调度任务时,会有最坏的时间复杂度O(n)。在方案6和方案7之间作比较,在设定比较大的轮盘值W时(W>n),并且任务均匀的散列到每个桶内时,都会有一个比较好的最好时间复杂度O(1),但是对于时间跨度比较大的情况(T>W)时,选择方案7会比较好,在时间跨度比较小(T<W)时,选择方案6会稍微好一些。
举个例子,对于最高峰值10000 qps的服务,检查每个请求是否在2s内过期,设定tick为1ms,T 的最大值为2000(ms),相对于方案7中的例子,时间跨度并不是很大,在选择轮盘大小时,我们甚至可以设置W为2048,依据上边的公式比较,所以选择方案6 会更合适。实际在现实例子中,使用时间轮来调度定时任务时,时间跨度都不会很大因此T一般都会小于W,所以方案6在绝大多数场景下都适用。
java中的几种实现
下面来看下几种典型的定时调度算法实现 :
java Timer
这是java库里最基础的,如文章开头所述有2个问题,不能调度太多的任务,而且精度也不准。根据java api文档,其内部实现是一个二叉堆,调度一个任务的时间复杂度是O(logn)
java ScheduledThreadPoolExecutor
这是java 5 开始引入的一个定时调度器,用来代替之前的Timer和TimerTask组合,这个调度器可以指定多个线程来执行调度任务。另外执行调度任务时,还可以catch住任务抛出的异常,还 不会影响其他任务的调度。另外还可以重载他的afterexecute方法来对异常做处理。
Netty时间轮io.netty.util.HashedWheelTimer
这是上边所述的方案6的典型实现,hash 时间轮加无序桶。 默认的时间轮盘值是512,tick time是100ms。如上所述,因为现实使用中,时间跨度度不会很大,方案6是适用于现实中绝大多数定时任务调度场景。
Kafka内置的时间轮
这是上边所述的方案7的典型实现,多级时间轮。kafka使用这个时间轮来实现消息的延迟生产、拉取等longpoll操作。
Title: 时间轮算法分析和应用
Author: Rex Wang rexwang735@gmail.com
Date: 2023-04-10
Last Update: 2024-03-24
Copyright Declaration: Plz credit the original source when reposting
Aktie